[목차]
1. 정규화가 생겨난 배경
2. 정규화란?
3. 반정규화란?
4. 함수 종속성
5. 이상현상(Anomaly)
1. 정규화가 생겨난 배경
한 릴레이션(Relation)에 여러 엔티티의 속성을 혼합하면 정보가 중복 저장되며 저장 공간을 낭비하게 된다.
또 중복된 정보로 인해 '이상 현상'이 발생하게 된다. 이러한 문제를 해결하기 위해 정규화 과정을 거치는 것이다.
2. 정규화란?
- Attribute 간의 종속성으로 인한 이상현상이 발생하는 릴레이션을 분해하여 재디자인함으로써 이상현상을 없애는 과정
- 데이터의 중복 방지, 무결성을 충족하기 위해 데이터베이스를 설계하는 방법
정규화에는 아래와 같은 3가지 원칙이 있다.
1. 정보의 무손실 : 분해된 릴레이션이 표현하는 정보는 분해되기 전의 정보를 모두 포함해야 한다.
2. 최소 데이터 중복 : 이상 현상을 제거, 데이터 중복을 최소화
3. 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현
정규화의 장점은 다음과 같다.
- 각종 이상 현상들을 해결할 수 있다.
- 새로운 속성의 추가로 인해 DB 구조를 확장하는 경우, 구조의 변경을 최소화할 수 있다. 따라서 DB와 연동된 응용프로그램에 최소한의 영향만을 미쳐 응용프로그램의 생명을 연장시킨다.
- 정규화된 릴레이션 간의 관계가 현실 세계에서의 개념들간의 관계를 잘 보여준다.
반면, 릴레이션의 분해로 인해 릴레이션간의 연산이 많아져 응답 시간이 오히려 느려질 수도 있는 단점이 있다.
이러한 경우 반정규화(De-normalization)을 통해서 성능을 향상시킬 수 있다.
3. 반정규화란?
반정규화(De-normalization)은 시스템의 성능 향상을 위해 정규화된 데이터 모델을 통합하는 작업으로, 의도적으로 정규화 원칙을 위배하는 행위이다. 따라서 정규화와 반정규화는 Trade-off 관계에 있다.
반정규화의 종류로는 테이블 통합/분할/추가, 중복 속성 추가 등이 있다.
반정규화를 수행하면 테이블이 단순해지고 관리 효율성이 증가하지만, 데이터의 일관성이나 무결성이 보장되지 않을 수 있다. 의도적으로 중복을 생성하여 검색 기능은 향상되지만, 갱신, 삭제 등의 성능은 낮아진다.
따라서 데이터의 중복 방지, 무결성 vs 데이터베이스의 성능, 단순화 사이의 우선순위를 잘 조절하여 정규화/반정규화를 수행해야 한다.
반정규화의 대상이 되는 경우는 다음과 같다.
1. 수행 속도가 많이 느린 경우
2. 테이블의 조인(JOIN)연산을 지나치게 사용하여 데이터를 조회하는 것이 기술적으로 어려운 경우
3. 테이블에 많은 데이터가 있고, 다량의 범위 혹은 특정 범위를 자주 처리해야 하는 경우
4. 함수 종속성
함수 종속성(Functional Dependency)은 어떤 테이블의 속성 A와 B에 대하여, A값에 의해 B값이 유일하게 정해지는 관계를 말하며, "B는 A에 함수 종속이다"라고 한다. A→B의 기호로 나타낸다.
이때, A를 결정자(Determinant)라고 하고, B를 종속자(Dependant)라고 한다.
함수 종속성은 크게 완전 함수 종속과 부분 함수 종속, 이행적 함수 종속으로 나뉜다.
- 완전 함수 종속 : 기본키를 구성하는 모든 속성에 종속되는 경우
- 부분 함수 종속 : 기본키를 구성하는 속성의 일부에 종속되거나, 기본키가 아닌 다른 속성에 종속되는 경우
- 이행적 함수 종속 : A, B, C 세 속성이 있고 A→B, B→C 종속 관계가 있을 때, A→C가 성립하는 경우

위와 같은 테이블이 있다고 하자. 여러 학생들이 있고 각 학생별로 여러 과목을 수강한다고 할 때, 위 테이블의 기본키는 (학번, 과목번호)가 될 것이다.
그렇다면, 이름과 학년은 학번만 알아도 유일하게 결정된다. 반면에 성적은 학번과 과목 번호를 모두 알아야 유일하게 결정된다. 따라서 그림으로 표현하면 다음과 같다.
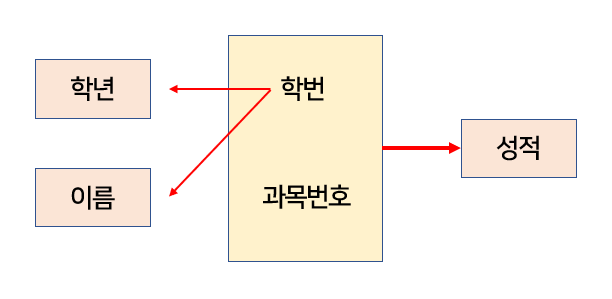
그러므로, 학년과 이름은 (학번, 과목번호)에 대해 부분 함수 종속이고, 성적은 완전 함수 종속이다.
이렇게 엔티티를 구성하는 속성간의 함수 종속성을 판단하여 좋은 릴레이션인지 알 수 있다.
5. 이상현상 (Anomaly)
이상현상이란, 테이블 내의 데이터들이 불필요하게 중복되어 테이블을 조작할 때 발생되는 데이터 불일치 현상이다.
테이블을 잘못 설계하여 삽입, 삭제, 갱신할 때 오류가 발생하게 되는 것이다. 이상현상에는 크게 3가지 이상현상이 있으며, 정규화를 통해서 이상현상들을 해결할 수 있다.
- 삽입 이상 (insertion anomaly) : 원하지 않는 자료가 삽입된다든지, key가 없어 삽입하지 못하는(불필요한 데이터를 추가해야 삽입할 수 있음) 문제점
- 삭제 이상 (deletion anomaly) : 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점
- 갱신 이상 (update anomaly) : 일부만 변경하여 데이터가 불일치하는 모순, 또는 중복되는 튜플이 존재하게 되는 문제점.

위와 같은 테이블을 예로 들어 어떤 이상현상이 발생하는지 알아보자.
1. 삽입 이상
- 강의를 수강하지 않은 학생을 추가할 때, 과목 번호와 성적에 null값이 들어가거나 불필요한 데이터를 추가해야 삽입할 수 있는 문제점이 발생한다. 아래와 같은 데이터를 삽입할 수 없다.

- 학생이 수강신청을 할 때 반드시 과목 번호를 알아야 삽입이 가능하다.
2. 삭제 이상
- 학번이 300인 학생이 과목 수강을 취소하면 C-73인 강의에 대한 정보도 모두 삭제된다.

- P1 교수가 강의하는 과목을 취소하는 경우 학번이 123인 학생에 대한 정보도 모두 삭제된다.
3. 갱신 이상
- 학번이 123인 학생의 지도교수가 P2로 변경되면, 123인 학생이 수강하는 모든 과목(행)에서의 지도교수를 변경시켜주어야 한다.
[참고]
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database
PC로 보시는 것을 권장합니다.
피드백은 언제나 환영입니다. 댓글로 달아주세요 ^-^
'Computer Science > 데이터베이스(DB)' 카테고리의 다른 글
| [DB] 9. 트랜잭션(Transaction) - (1) 특성, ACID, 연산, 상태 (1) | 2021.08.10 |
|---|---|
| [DB] 8. 정규형 (1NF, 2NF, 3NF, BCNF) (108) | 2021.08.04 |
| [DB/SQL] 프로그래머스 MySQL 문제 (LEVEL 2) 풀이 (1) (86) | 2021.07.09 |
| [DB/SQL] 프로그래머스 MySQL 문제 (LEVEL 1) 풀이 (87) | 2021.07.07 |
| [DB/SQL] 6. 집계 함수(Aggregate Function), GROUP BY, HAVING (87) | 2021.07.06 |



