[목차]
1. B-Tree란?
2. B-Tree의 key 검색
3. B-Tree의 key 삽입
4. B-Tree의 key 삭제
참고)
https://hyungjoon6876.github.io/jlog/2018/07/20/btree.html
https://helloinyong.tistory.com/296
1. B-Tree란?
B-Tree는 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종이다. 모든 leaf node가 같은 level로 유지되도록 자동으로 밸런스를 맞춰준다. 자식 node의 개수가 2개 이상이며, node 내의 key가 1개 이상일 수 있다.
node의 자식 수 중 최댓값을 K라고 하면, 해당 B-Tree를 K차 B-Tree라고도 한다.
B-Tree의 조건은 다음과 같다.
1. node의 key의 수가 k개라면, 자식 node의 수는 k+1개이다.
2. node의 key는 반드시 정렬된 상태여야 한다.
3. 자식 node들의 key는 현재 node의 key를 기준으로 크기 순으로 나뉘게 된다.
4. root node는 항상 2개 이상의 자식 node를 갖는다. (root node가 leaf node인 경우 제외)
5. M차 트리일 때, root node와 leaf node를 제외한 모든 node는 최소 $\left \lceil \frac{M}{2} \right \rceil$, 최대 $M$개의 서브 트리를 갖는다.
6. 모든 leaf node들은 같은 level에 있어야 한다.

위의 트리는 3차 B-Tree의 예시이다. 주황색 부분은 '자식 node를 가리키는 포인터'이고, 살구색 부분은 '각 node의 key'이다. key와 데이터가 1대1 대응하고 있다.
node 안에서 key들은 항상 정렬된 상태를 유지하며, 이진 탐색 트리처럼 항상 각 key의 왼쪽 자식은 자신보다 작고, 오른쪽 자식은 자신보다 크다.
Balanced tree를 사용하는 이유는 뭘까?
일반적인 트리인 경우 탐색하는데 평균적인 시간 복잡도로 O(logN)을 갖지만, 트리가 편향된 경우 최악의 시간복잡도로 O(N)을 갖게 된다.

root node부터 탐색을 한다고 가정하고, 왼쪽처럼 편향된 트리에서 leaf node까지 탐색한다면 모든 node를 방문하기 때문에 O(N)의 시간이 걸리게 된다. 이러한 단점을 보완하기 위해 트리가 편향되지 않도록 항상 밸런스를 유지하는 트리가 필요하다. 자식들의 밸런스를 잘 유지하면 최악의 경우에도 O(logN)의 시간이 보장된다.
2. B-Tree의 key 검색
그렇다면 원하는 값은 어떻게 찾을까?
이는 이진 탐색 트리에서와 비슷하다. 원하는 값을 K라고 가정하자.
1) root node부터 탐색을 시작한다.
2) node의 key를 순회하여 K가 존재하면 탐색을 종료한다.
3) k가 존재하지 않는다면, 어떤 이웃한 두 key 사이에 K가 들어가는 경우 사이의 포인터를 통해 자식 node로 내려간다.
4) leaf node까지 2~3을 반복한다.
예를 들어 위의 B-Tree 예시에서 14라는 key를 검색한다고 가정해보자. 아래와 같이 진행된다.





실제 데이터베이스에선 한 node에 매우 많은 key가 포함될 수 있기 때문에, 정렬되어 있음을 이용하여 binary search 등으로 효과적으로 찾을 수 있다.
3. B-Tree의 key 삽입
B-Tree는 균형을 유지해야 하기 때문에 key를 삽입하는 경우 트리의 변형이 발생할 수 있다. 삽입하는 과정은 다음과 같다.
1. 빈 트리인 경우 root node를 만들어 K를 삽입한다. root node가 가득 찬 경우 node를 분할하여 leaf node를 생성한다.
2. K가 들어갈 leaf node를 검색 과정과 동일하게 탐색한다.
3. 해당 leaf node에 자리가 남아있다면 정렬을 유지하도록 알맞은 위치에 삽입하고, leaf node가 꽉 차 있다면 K를 삽입한 후 해당 node를 분할한다.
4. node가 분할되는 경우 node의 중앙값을 기준으로 분할한다. 중앙값은 부모 node로 합쳐지거나 새로운 node로 생성되고, 중앙값을 기준으로 왼쪽의 key는 왼쪽 자식, 오른쪽의 key는 오른쪽 자식으로 생성된다.
마찬가지로 동일한 B-Tree에서 13이라는 key를 삽입해보자. 검색하는 과정은 생략하였다.








4. B-Tree의 key 삭제
특정 key를 삭제하는 경우도 마찬가지로 균형을 유지하기 위해서 트리의 변형이 필요하다. 삽입하는 과정보다는 조금 더 복잡하다.
삭제되는 key가 어느 node에 속해있는지, node의 상태는 어떤지에 따라 삭제되는 방식이 조금씩 다르다. 경우는 다음과 같이 나눠진다.
1. 삭제할 key가 leaf node에 있는 경우
1-1) 현재 node의 key 수가 최소보다 큰 경우
1-2) 현재 node의 key 수가 최소이고, 왼쪽 또는 오른쪽 형제 node의 key 수가 최소보다 큰 경우
1-3) 현재 node와 왼쪽, 오른쪽 형제 node의 key 수가 최소이고, 부모 node의 key 수가 최소보다 큰 경우
1-4) 현재 node와 왼쪽, 오른쪽 형제 node, 부모 node 모두 key 수가 최소인 경우
2. 삭제할 key가 leaf node를 제외한 node에 있는 경우
2-1) 현재 node 또는 자식 node의 key 수가 최소보다 큰 경우
2-2) 현재 node와 자식 node 모두 key 수가 최소인 경우
설명의 편의를 위해 용어를 다음과 같이 임의로 정의했다.
Lmax := 현재 node의 왼쪽 자손 중 가장 큰 key
Rmin := 현재 node의 오른쪽 자손 중 가장 작은 key
par := 현재 node를 가리키는 부모 node의 포인터의 오른쪽에 있는 key. 가장 우측에 있는 포인터인 경우 왼쪽에 있는 key
K := 삭제할 key
1. 삭제할 key가 leaf node에 있는 경우
1-1) 현재 node의 key 수가 최소보다 큰 경우
leaf node이면서 현재 node의 key 수가 최소보다 큰 경우에는 단순히 삭제해도 무방하다.
1-2) 현재 node의 key 수가 최소이고, 왼쪽 또는 오른쪽 형제 node의 key 수가 최소보다 큰 경우
K를 par로 바꿔준다. 그리고 par를 왼쪽 형제 node의 key 수가 최소보다 크다면 Lmax로, 오른쪽 형제 node의 key 수가 최소보다 크다면 Rmin로 바꿔준다.
ex) K = 10

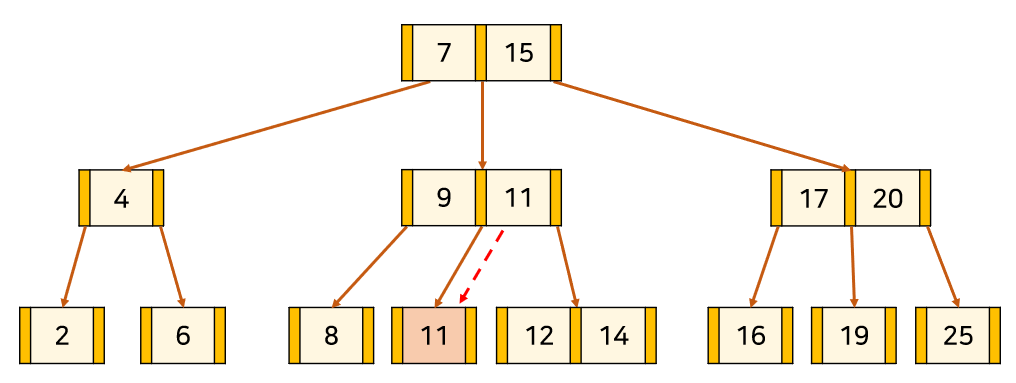

1-3) 현재 node와 왼쪽, 오른쪽 형제 node의 key 수가 최소이고, 부모 node의 key 수가 최소보다 큰 경우
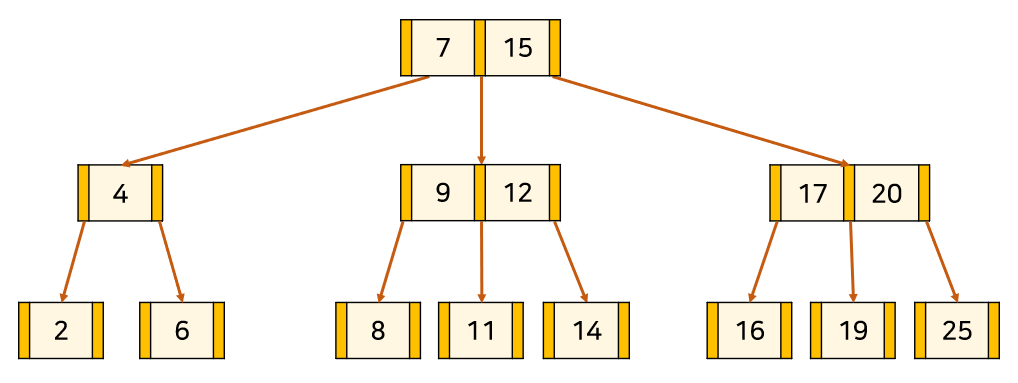
K를 삭제하고, par를 부모 node에서 분할하여 형제 node와 합쳐준다. 그러면 부모 node의 key 수가 하나 줄고, 자식 node의 수도 하나 줄어들어 B-Tree 조건을 유지한다.
ex) K = 16



1-4) 현재 node와 왼쪽, 오른쪽 형제 node, 부모 node 모두 key 수가 최소인 경우
부모 node가 root인 subtree의 높이가 줄어들기 때문에 트리의 재구조화가 필요하다.
이 경우는 2-2) 경우와 동일하므로 뒤에서 함께 설명하겠다.
2. 삭제할 key가 leaf node를 제외한 node에 있는 경우
2-1) 현재 node 또는 자식 node의 key 수가 최소보다 큰 경우
K의 Lmax 또는 Rmin과 자리를 바꿔준다. 그러고 나면 leaf node에서의 K 삭제와 동일해진다.
ex) K = 15


2-2) 현재 node와 자식 node 모두 key 수가 최소인 경우
현재 node와 자식 node가 모두 key 수가 최소라면, K를 삭제하는 경우 B-Tree 조건을 만족하기 위해서 트리의 높이를 줄여야 한다. 즉, 트리를 재구조화하며 그 과정은 다음과 같다.
1. K를 삭제하고 K의 양쪽 자식을 하나로 합친다. 합쳐진 node를 n1이라고 하자.
2. K의 par를 K의 형제 node에 합쳐준다. 합쳐진 node를 n2라고 하자.
3. n1을 n2의 자식이 되도록 연결한다.
4-1. 만약 n2의 key 수가 최대보다 크다면 key 삽입 과정과 동일하게 분할을 한다.
4-2. 만약 n2의 key 수가 최소보다 작다면 2.로 돌아가서 동일한 과정을 반복한다. (n2의 par를 n2의 형제 node에 합쳐준다)
ex) K = 4






PC로 보시는 것을 권장합니다.
피드백은 언제나 환영입니다. 댓글로 달아주세요 ^-^
'Computer Science > 데이터베이스(DB)' 카테고리의 다른 글
| [DB] 11. 인덱스(Index) - (1) 개념, 장단점, B+Tree 등 (10) | 2021.08.31 |
|---|---|
| [DB] 9. 트랜잭션(Transaction) - (4) 고립화 수준, 회복 기법 (4) | 2021.08.12 |
| [DB] 9. 트랜잭션(Transaction) - (3) 병행 제어, 로킹, 타임스탬프 (3) | 2021.08.12 |
| [DB] 9. 트랜잭션(Transaction) - (2) 트랜잭션 스케줄 & 충돌, 뷰 직렬 (0) | 2021.08.12 |
| [DB] 9. 트랜잭션(Transaction) - (1) 특성, ACID, 연산, 상태 (1) | 2021.08.10 |



