[목차]
1. Process
2. Process State
3. Process Control Block (PCB)
4. Context Switch
5. Process Scheduling
6. Process Management
7. Cooperating Processes
참고)
- https://parksb.github.io/article/7.html
- KOCW 공개강의 (2014-1. 이화여자대학교 - 반효경)
- Sogang Univ. Operating System Lecture Note (2018-2. Prof. Youngjae Kim)
1. Process
프로세스(Process)는 쉽게 말해 '실행 중인 프로그램'이다. 더 정확히 말하면, 디스크에 있는 프로그램이 메모리에 로드되면 프로세스가 된다. 하나의 프로그램이 여러 프로세스가 될 수 있다.
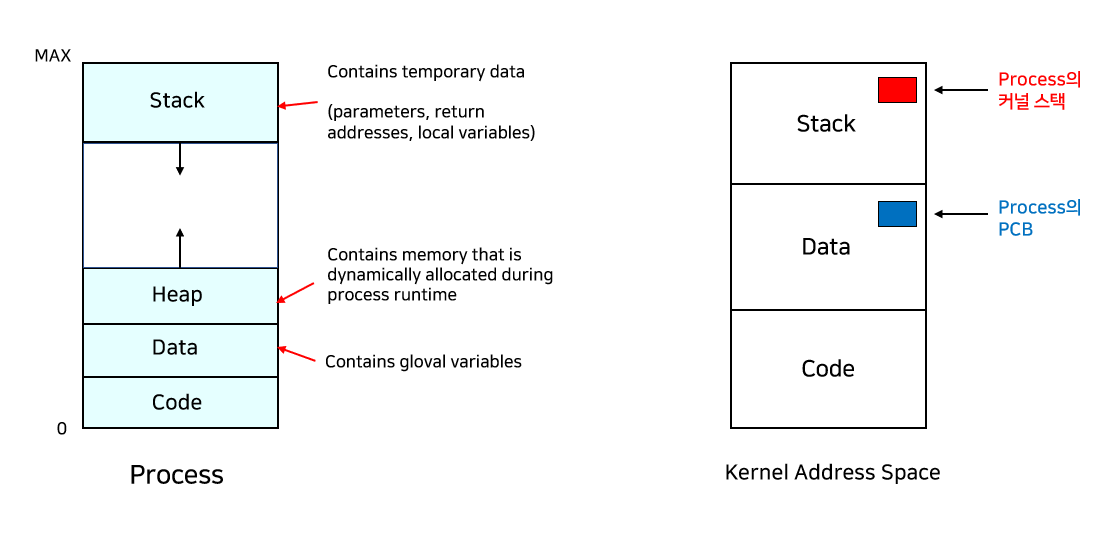
프로세스는 스택(Stack), 힙(Heap), 데이터(Data), 코드(Code)로 나뉜다.
프로세스 문맥(Process Context)은 Process의 특정 시점의 상태를 표현하는 정보이다.
먼저, 하드웨어 문맥(Hardware Context)으로는 프로그램 카운터(Program Counter), 각종 레지스터(Register)가 있다. 이들을 이용하여 해당 프로세스가 어디까지 실행되었는지를 알 수 있다.
그리고, 프로세스의 주소 공간(Address space)도 문맥에 포함되며, 프로세스 관련 커널 자료구조인 PCB(Process Control Block), 프로세스 커널 스택(Process Kernel Stack)도 포함된다.
2. Process State
프로세스의 상태는 프로세스가 실행됨에 따라 달라진다.
1. New : 프로세스가 처음 생성된 상태
2. Ready : 프로세스가 CPU에 할당되기를 기다리는 상태 (메모리 등 다른 조건을 모두 만족하고)
3. Running : 프로세스가 할당되어 CPU를 잡고 명령을 수행 중인 상태
4. Waiting : 프로세스가 어떠한 이벤트가 발생하기를 기다리는 상태. CPU를 할당해도 당장 명령을 수행할 수 없는 상태.
5. Terminated : 프로세스가 실행을 마쳤을 때. 아직 완전히 프로세스가 제거되진 않은 상태.


3. Process Control Block (PCB)
PCB(Process Control Block)는 운영체제가 각 프로세스를 관리하기 위해 프로세스별로 보유하고 있는 자신의 정보 묶음이다. 커널의 주소 공간에 있으며 다음의 구성 요소를 갖는다.
1. 운영체제가 관리상 사용하는 정보
- Process state
- Process ID
- Scheduling information : 프로세스의 중요도, 스케줄링 큐 포인터 등 스케줄링 파라미터 정보
- Priority : 프로세스의 우선순위
2. CPU 수행 관련 하드웨어 값
- Program counter : 해당 프로세스가 이어서 실행해야 할 명령의 주소를 가리키는 포인터
- Register : 프로세스가 인터럽트 이후 올바르게 작업을 이어가기 위해 참조하는 CPU 레지스터 값
3. 메모리 관련
- Code, Data, Stack의 위치 정보, base/limit 레지스터 값
4. 파일 관련
- open file descriptors : 열린 파일 목록

4. Context Switch
Context Switch(문맥 교환)는 프로세스가 실행되다가 인터럽트가 발생해 CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 과정이다. 운영체제는 CPU를 내어주는 프로세스의 상태를 그 프로세스의 PCB에 저장하고, CPU를 새롭게 얻는 프로세스의 상태를 PCB에서 읽어온다.
즉, CPU입장에서 Context는 PCB이기 때문에 PCB 정보가 바뀌는 것이 Context Switch이다.
다만, 시스템 콜이나 인터럽트가 발생한다고 반드시 Context Switch가 일어나는 건 아니다. 다른 프로세스에 프로세서가 넘어가야 Context Switch이다.

위의 경우에도 CPU 수행 정보 등 context의 일부를 PCB에 저장해야 하지만, context switch의 overhead가 훨씬 크기 때문에 아래의 경우가 overhead가 더 크다.
5. Process Scheduling
멀티프로그래밍(Multiprogramming)의 목적은 CPU를 최대한 사용하기 위해 몇몇 프로세스를 항상 실행시키는 것이다. 시간 공유(Time Sharing)의 목적은 프로세스 간에 CPU를 빠르게 전환함으로써 사용자가 각 프로그램이 실행되는 동안 서로 상호작용할 수 있도록 만드는 것이다.
이러한 목적을 달성하기 위해 프로세스 스케줄러는 CPU에서 프로그램 실행을 위해 사용 가능한 프로세스를 선택한다. 이렇게 어떤 프로세스를 프로세서에 할당할 것인가를 결정하는 일을 프로세스 스케줄링(Process Scheduling)이라고 한다.
프로세서가 하나인 시스템은 오직 하나의 running 프로세스를 가질 수 있고, 여러 프로세스가 존재하는 경우 나머지는 CPU가 free 상태가 될 때까지 기다려야 하기 때문에 적절한 프로세스 스케줄링이 필요하다.
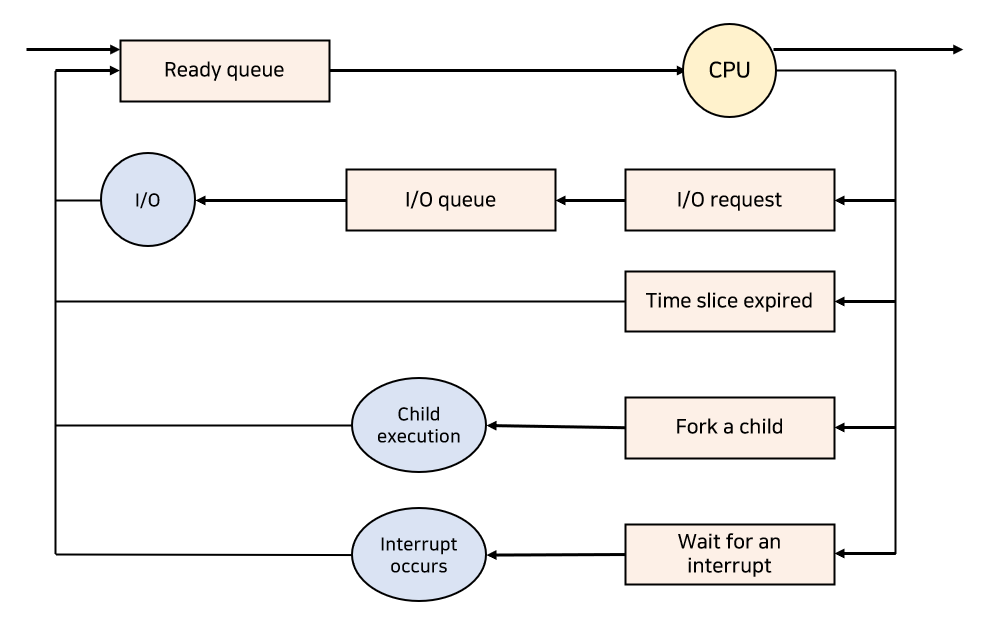
프로세스를 스케줄링하기 위한 큐(Queue)로는 Job Queue, Ready Queue, Device Queue가 있다. 프로세스가 이 큐들을 이용하여 수행된다.
Job Queue는 하드디스크에 있는 프로그램이 실행되기 위해 메인 메모리의 할당 순서를 기다리는 큐이다. Ready Queue는 현재 메모리 내에 있으면서 CPU를 잡아서 실행되기를 기다리는 프로세스의 집합이다. 그리고 Device Queue는 I/O 장치를 기다리는 프로세스의 집합이다.
스케줄러의 종류로는 다음과 같이 3가지로 구분된다.
1. Long-Term Scheduler (장기 스케줄러 or Job Scheduler)
시작 프로세스 중 어떤 프로세스를 Ready Queue로 보낼지를 결정하며, 프로세스에 메모리 및 각종 자원을 할당한다. 자주 발생하지는 않는다. 또 Degree of Multiprogramming(메모리에 몇 개의 프로세스가 존재하는지)를 제어한다.
Time-sharing 시스템에서는 보통 Long-Term Scheduler가 존재하지 않고 무조건 Ready Queue로 올라가는 방식이다.
2. Short-Term Scheduler (단기 스케줄러 or CPU Scheduler)
어떤 프로세스를 다음에 실행시킬지를 선택하며, 프로세스에 CPU를 할당한다. 자주 발생하는 작업이므로 충분히 빨라야 한다.
3. Medium-Term Scheduler (중기 스케줄러 or Swapper)
프로세스를 수행하다가 메모리에서 잠시 제거했다가 시간이 지난 후 다시 메모리에 넣고 수행을 이어나가는 것이 더 이득이 될 수 있는 경우가 존재할 수 있다. 이를 위해 프로세스를 통째로 메모리에서 디스크로 쫓아내서 여유 공간을 마련하는 작업을 Swapping이라고 한다. 즉, 프로세스에게서 메모리를 뺏는다. 이 작업을 Medium-Term Scheduler가 수행한다. Degree of Multiprogramming을 제어한다.
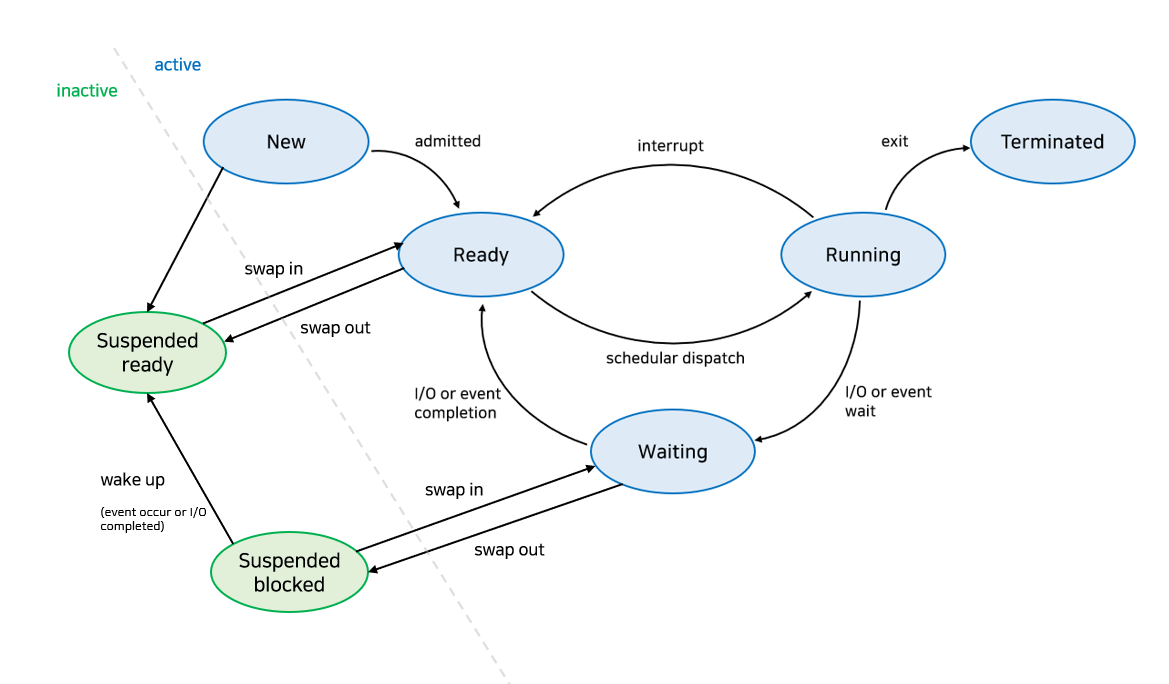
중기 스케줄러에 의해 프로세스의 Suspended(Stopped)라는 상태를 추가적으로 나타낼 수 있다.
이는 외부적인 이유로 프로세스의 수행이 중지된 상태이다. Waiting 상태와 유사하지만 차이가 있는데, Waiting은 자신이 요청한 이벤트가 만족되면 Ready 상태로 돌아가지만, Suspended는 외부에서 다시 시작을 해주어야 활성화가 된다.
따라서 이를 반영한 프로세스의 상태표는 다음과 같다.
6. Process Management
대부분의 시스템에서 프로세스는 동시에 실행될 수 있고, 이들은 동적으로 생성되거나 삭제될 수 있다.
1. Process Creation (프로세스 생성)
프로세스는 부모 프로세스가 자식 프로세스를 생성하는 방식이다. 따라서 프로세스는 트리(계층) 구조로 되어있다.
프로세스는 PCB에 저장된 pid(process identifier)값을 통해서 식별되고 관리된다. 또 프로세스는 자원이 필요한데, 자원은 운영체제로 부터 받거나 부모와 공유한다.
프로세스는 다음과 같이 각 특성마다 분류가 된다.
▶ 자원 공유 (Resource sharing option)
- 부모와 자식이 모든 자원을 공유하는 모델
- 부모와 자식이 자원의 일부를 공유하는 모델
- 전혀 공유하지 않는 모델
▶ 수행 (Execution)
- 부모와 자식이 공존하며 동시에 수행되는 모델
- 자식이 종료될 때까지 부모가 기다리는 모델
▶ 주소 공간(Address space)
- 자식이 부모의 공간을 복제하는 모델
- 자식이 해당 공간에 새로운 프로그램을 올리는 모델
UNIX를 예로 들어보자.
1) fork
프로세스의 생성은 fork( ) 시스템 콜을 이용한다. fork( )를 이용하면 부모를 그대로 복사하여 현재 프로세스와 pid만 다른 프로세스를 생성한다. 즉, 같은 동작을 하는 프로세스가 두 개 존재하게 되며, 새로운 프로세스는 원래의 프로세스 주소 공간의 복사본을 포함한다.
두 프로세스는 fork( ) 뒤의 명령어들을 계속 수행한다. 이때 현재 프로세스가 부모 프로세스인지 자식 프로세스인지는 fork( )의 반환 값으로 구분한다. 부모는 fork()의 반환 값으로 0보다 큰 수(자식 프로세스의 pid)를 갖고, 자식은 fork()의 반환 값으로 0을 갖는다.
fork는 heavy-weight 한 시스템 콜이다. 부모 프로세스의 전체 복사본을 생성하고, 이를 자식 프로세스로 실행시키기 때문이다. 따라서 이 수행에 필요한 노력을 줄이기 위해 copy-on-write 기술을 사용한다.
copy-on-write는 복사하는 작업을 부모나 자식이 page에 쓰기 작업을 하기 전까지 copy 작업을 지연시킴으로써 효율성을 높여주는 기술이다. 부모 프로세스가 fork 하여 생긴 자식 프로세스의 page를 공유하다가 자식이 page에 쓰기 작업을 할 때 해당 page만을 copy 하는 방식이다. 이를 통해 전체가 복사되는 현상을 방지한다.
copy-on-write는 프로세스들이 일반적으로 메모리에서 page의 일부분만을 사용한다는 사실을 이용한 기술이다.
반면 단점도 있다. 많은 양의 RAM이 사용되며, copy를 하는 시간이 오래 걸린다. 그리고 프로세스를 copy 하자마자 exec을 통해 새로운 프로그램을 로드하는 경우 단점이 극대화된다.
이러한 단점을 커널이 프로세스의 전체 주소 공간이 아니라 오직 page table만 복사함으로써 극복한다. page table에 대한 자세한 설명은 후반부 챕터에서 다룬다.
vfork라는 시스템 콜도 존재한다. fork와 유사하지만, 부모 프로세스의 복사본을 생성하지 않고 부모와 자식 사이에 데이터를 공유하는 방식이다. 이를 통해 CPU time을 많이 줄일 수 있다. 만약 한 프로세스가 데이터를 조작하려고 하면 다른 프로세스도 자동으로 인지하게 된다.
vfork는 자식 프로세스가 생성된 다음 즉시 새로운 프로그램을 로드하기 위해서 exec( )을 호출해야 하는 상황을 위해 고안되었다. 다만, fork에 copy-on-write 기술을 사용하기 때문에 실제로 vfork가 특별히 유용하지 않고 잘 쓰지도 않는다.
2) exec
fork( ) 다음에 이어지는 exec( ) 시스템 콜은 새로운 프로그램을 메모리에 올려 실행시킨다. exec( ) 시스템 콜은 어떤 프로그램을 완전히 새로운 프로세스로 태어나도록 하는 역할을 하며, 프로세스는 exec( ) 시스템 콜을 통해 다른 프로그램을 수행할 수 있다. 따라서 기존엔 부모 프로세스를 그대로 복사한 상태지만 exec( ) 시스템 콜로 인해 다른 새 프로그램으로 덮어씌워진다.

이처럼 fork 함수의 반환 값을 이용해서 만약 child인 경우 새로운 프로그램을 실행시키고 싶다면 exec( ) 시스템 콜을 사용하면 된다. exec( ) 시스템 콜을 사용하는 경우, 그 뒤의 명령어는 수행하지 않는다. 즉, /* CODE */ 에 해당하는 부분은 수행하지 않는다.
3) wait
wait( ) 시스템 콜은, 만약 프로세스 A가 wait( )를 호출하면 커널은 자식이 종료될 때까지 A를 Sleep(blocked)시킨다. 그리고 자식 프로세스가 종료되면 커널이 A를 깨워 Ready 상태로 만든다.
따라서 만약 자식이 먼저 수행되기를 원하면 위와 같이 wait( )를 else문에 넣어주면 된다.

2. Process Termination (프로세스 종료)
1) 자발적 종료
현재 프로세스가 마지막 statement를 수행하면, 운영체제에 exit() 명령어를 통해서 이를 알려준다.
그러면 부모 프로세스가 현재 프로세스의 실행을 종료시키고, wait를 통해 자식으로부터 상태 값(status value)을 수집한다. 프로세스의 각종 자원들은 운영체제에 반납된다.
2) 비자발적 종료 (kill)
부모 프로세스가 자식 프로세스의 수행을 종료시킬 수도 있다. 자식이 할당된 자원의 한계치를 넘어서거나, 자식에게 할당된 작업이 더 이상 필요하지 않거나, 부모 프로세스가 종료되는 경우이다.
운영체제는 부모 프로세스가 종료되는 경우 자식이 계속 수행되는 것을 허용하지 않기 때문에 단계적으로 자식들을 종료시켜나간다.
프로세스의 비정상적인 종료로 인해 Zombie process나 Orphan process 같은 유형의 프로세스가 존재할 수 있다.
Zombie process는 실행이 끝났지만 프로세스 테이블에 엔트리(Entry)를 가지고 있는, 정보가 메모리에 남아있는 프로세스를 말한다. 프로세스가 종료되었지만 버그나 에러로 인해 해당 프로세스의 부모가 아직 wait를 통해서 상태를 수집하지 못한 경우이다. 모든 프로세스는 아주 잠깐 좀비의 상태로 존재할 수 있다.
Orphan process는 부모가 wait를 호출하지 않고 종료되었을 때의 자식 프로세스를 의미한다. 즉, 부모는 종료되었지만 자식은 수행 중인 경우이다. 이런 경우엔 init process가 orphan process들의 새로운 부모로 할당되고, init process가 주기적으로 wait를 호출해서 orphan process들의 exit status를 수집한다.
7. Cooperating Processes
프로세스는 동작하는 방식에 따라 독립적 프로세스(Independent Process), 협력 프로세스(Cooperating Process)로 나뉜다. 독립적 프로세스는 각자 주소 공간을 가지고 수행되며, 원칙적으로 하나의 프로세스는 다른 프로세스의 수행에 영향을 미치지 못한다. 반면 협력 프로세스는 프로세스 협력 메커니즘(IPC, Interprocess Communication)을 통해 하나의 프로세스가 다른 프로세스 수행에 영향을 미칠 수 있다. 협력의 이점으로는 정보 공유, 계산속도 향상, 편리함 등이 있다.
프로세스 협력 메커니즘(IPC, Interprocess Communication)에는 크게 두 모델이 있다.

1. 공유 메모리(Shared Memory)
서로 다른 프로세스 간에 일부 주소 공간을 공유하게 하는 방식이다. 커널을 거치지 않기 때문에 속도가 빠르지만 메모리에 동시에 접근하는 것을 방지하기 위해 별도의 구현이 필요하다.
2. 메시지 패싱(Message Passing)
메시지 패싱은 동일한 주소 공간을 공유하지 않고 커널을 통해 메시지를 주고받는다. Context Switch가 발생하기 때문에 속도가 느리지만, 커널이 기본 기능을 제공하기 때문에 공유 메모리 방식보다 구현이 쉽다. 메시지 패싱에서도 두 방식으로 나뉜다. 기본적으로 Send/Receive 작업을 통해 메시지를 교환해야 한다.
1) Direct Communication
Direct Communication은 통신하려는 프로세스의 이름을 명시적으로 표시해야 한다.

통신하고자 하는 모든 프로세스의 쌍들 사이에 자동으로 링크(link)가 생성된다. 따라서 프로세스들은 오직 서로의 이름만 알면 된다. 링크는 오직 두 프로세스에만 관련되며 주로 양방향이지만 단방향일수도 있다.
Direct Communication은 반드시 프로세스의 이름을 알아야 하는 단점이 있으며, 제한된 모듈성(Modularity)을 가진다. 모듈성이란 구성요소의 일부를 변경할 때 전체에 영향을 미치지 않도록 일부만 바꿀 수 있도록 설계되어 있는 것을 말하는데, 어떤 프로세스의 이름을 변경한다면 연결되어있는 모든 Sender와 Receive 프로세스를 바꿔야 하기 때문이다.
2) Indirect Communication
Indirect Communication은 mailbox를 통해 메시지를 전달한다.

각각의 mailbox는 unique 한 ID를 가지고 있다. 프로세스들은 서로 mailbox를 공유하고 있는 경우 링크가 생성되어 통신할 수 있다. 마찬가지로 양방향, 단방향 모두 가능하고 하나의 링크가 셋 이상의 프로세스와 관련될 수 있다. (one-to-many, many-to-one, many-to-many)
메시지 패싱은 동기화 문제를 해결하기 위해 Blocking 방식과 Non-blocking 방식이 사용된다.
Blocking은 동기식, Non-blocking은 비동기식으로 간주된다.
Blocking send : 수신자(프로세스 or mailbox)가 메시지를 받을 때까지 발신자는 block 된다.
Non-blocking send : 발신자가 메시지를 보내고 작업을 계속한다.
Blocking receive : 수신자가 메시지를 받을 때까지 block 된다.
Non-blocking receive : 수신자는 유효한 메시지 또는 null 메시지를 받는다.
프로세스 사이에서 교환되는 메시지들은 임시 큐(Temporary Queue)에 거주한다. 임시 큐는 다음의 세 방법 중 하나로 구현된다.
- Zero capacity (0 messages) : 발신자는 반드시 수신자를 기다려야 한다.
- Bounded capacity (finite length of n message) : 링크가 꽉 찬다면 발신자는 기다려야 한다.
- Unbounded capacity (infinite length) : 발신자는 전혀 기다리지 않는다.
프로세스끼리 통신할 때 파이프(Pipe)라는 방식으로도 통신한다. 말 그대로 프로세스 사이에 파이프를 두고 정보를 주고받는데, 파이프는 단방향 통신만 가능하기 때문에 양방향으로 정보를 주고받으려면 두 개의 파이프가 필요하다.
Anonymous 파이프와 named 파이프로 구분되는데, Anonymous는 부모-자식 또는 공통의 부모를 갖는 프로세스끼리만 통신 가능하다. 반면 named 파이프는 관계없이 사용할 수 있다.
단방향이기 때문에 데이터는 파이프의 한쪽 끝에선 써지고, 한쪽 끝에선 읽힌다. FIFO인 큐와 유사한 방식이다.
파이프에 포함된 데이터의 크기나 수신자/발신자는 알 수 없다. 파이프로의 접근은 파일 서술자(File descriptor)를 통해 가능하다.
'Computer Science > 운영체제(OS)' 카테고리의 다른 글
| [운영체제(OS)] 6. 프로세스 동기화(Process Synchronization) (2) | 2021.09.23 |
|---|---|
| [운영체제(OS)] 5. 프로세스 스케줄링(Process Scheduling) (1) | 2021.09.15 |
| [운영체제(OS)] 4. 멀티쓰레드(Multithreaded Programming) (1) | 2021.09.14 |
| [운영체제(OS)] 2. 시스템 구조(System Structures) (0) | 2021.09.06 |
| [운영체제(OS)] 1. Overview (0) | 2021.09.03 |



